Introduction
Azure Databricks is a first-party Microsoft Azure service that integrates the Databricks unified data analytics platform with Azure cloud services. It combines a managed Apache Spark environment, collaborative notebooks, and native integrations with Azure services (Storage, ADLS, Synapse, Data Factory, Key Vault, ML tools) so teams can build data pipelines, analytics, and AI/ML solutions faster and at scale.
Databricks (the company/platform) has seen rapid adoption and investment recently, reflecting demand for lakehouse and AI infrastructure across industries. For example, Databricks reported large funding and growth signals in 2025 and serves thousands of enterprise customers.
What is Azure Databricks?
-
Core idea: a managed, highly optimized Apache Spark platform delivered as a PaaS on Azure that simplifies building, scheduling, and scaling data pipelines and ML workflows.
Key components:
- Workspaces & notebooks (collaborative Python/Scala/SQL/R notebooks)
- Clusters (auto-scaling Spark clusters managed by the service)
- Jobs (scheduled pipelines)
- Delta Lake & Lakehouse support (transactional, ACID storage on top of cloud object stores)
- Integrations with Azure Data Factory, Azure Synapse, Azure Blob/ADLS, Key Vault, Azure ML, and Azure Active Directory for security.
Because it’s deeply integrated with the Azure ecosystem, teams using Azure for cloud infra find Azure Databricks convenient to adopt for data engineering, analytics, and ML.

Why take Azure Databricks training?
- Get practical with Spark on a managed platform: Databricks abstracts a lot of cluster management pain while exposing Spark APIs and performance tuning options.
- Work-ready skills: Many modern data engineering/ML roles expect experience with Spark, Delta Lake, and cloud-native data pipelines — training provides hands-on labs and projects.
- Faster to prototype ML & analytics: Collaborative notebooks, built-in MLflow tracking, experiment tracking, and integration with Azure ML speed model development.
- Demand & hiring: Large enterprises (and consulting firms) continue to hire Databricks-skilled engineers — training increases employability.
- Certifiable skills: Databricks offers certifications that validate proficiency — useful on résumés and for career progression.
Who can do Azure Databricks training?
- Data engineers who need to design and implement ETL/ELT pipelines and optimize Spark jobs.
- Data scientists who want to scale training and inference with Spark and Databricks’ ML tooling.
- Developers transitioning to data/ML roles.
- BI analysts who want to use large-scale SQL analytics on Delta Lake.
- IT/DevOps and architects who need to design secure, governed data platforms on Azure.
- Freshers with basic programming and SQL knowledge can begin with beginner courses and gradually move to advanced topics.
Course outcomes — what you will be able to do after training
A well-structured Azure Databricks course should leave you able to:
- Spin up and configure Databricks workspaces and clusters on Azure.
- Develop notebooks in Python/Scala/SQL and run scalable data pipelines.
- Use Delta Lake for ACID guarantees, time travel, and schema enforcement.
- Optimize Spark jobs (partitioning, caching, broadcast joins, shuffle tuning).
- Build scheduled jobs and orchestrate pipelines with Azure Data Factory or Databricks Jobs.
- Experiment & track models using MLflow and integrate with Azure ML (or other ML infra).
- Apply security best practices: role-based access, Key Vault secrets, network controls (VNet).
- Prepare for Databricks certification exams and for job interviews.
Career opportunities in Azure Databricks
Typical roles that seek Databricks skills:
- Azure Databricks Data Engineer
- Big Data Engineer / Spark Engineer
- Data Platform Engineer
- Machine Learning Engineer (when combined with ML/AI skills)
- Data Architect (for platform design roles)
- Analytics Engineer / BI Engineer
Companies across industries hire Databricks talent — enterprise customers and system integrators/consultancies (examples of major customers and employers include large enterprises such as Shell, AT&T, Toyota, Adobe — Databricks lists many enterprise customers and the company continues large-scale hiring).
Salary package — Experience vs Package
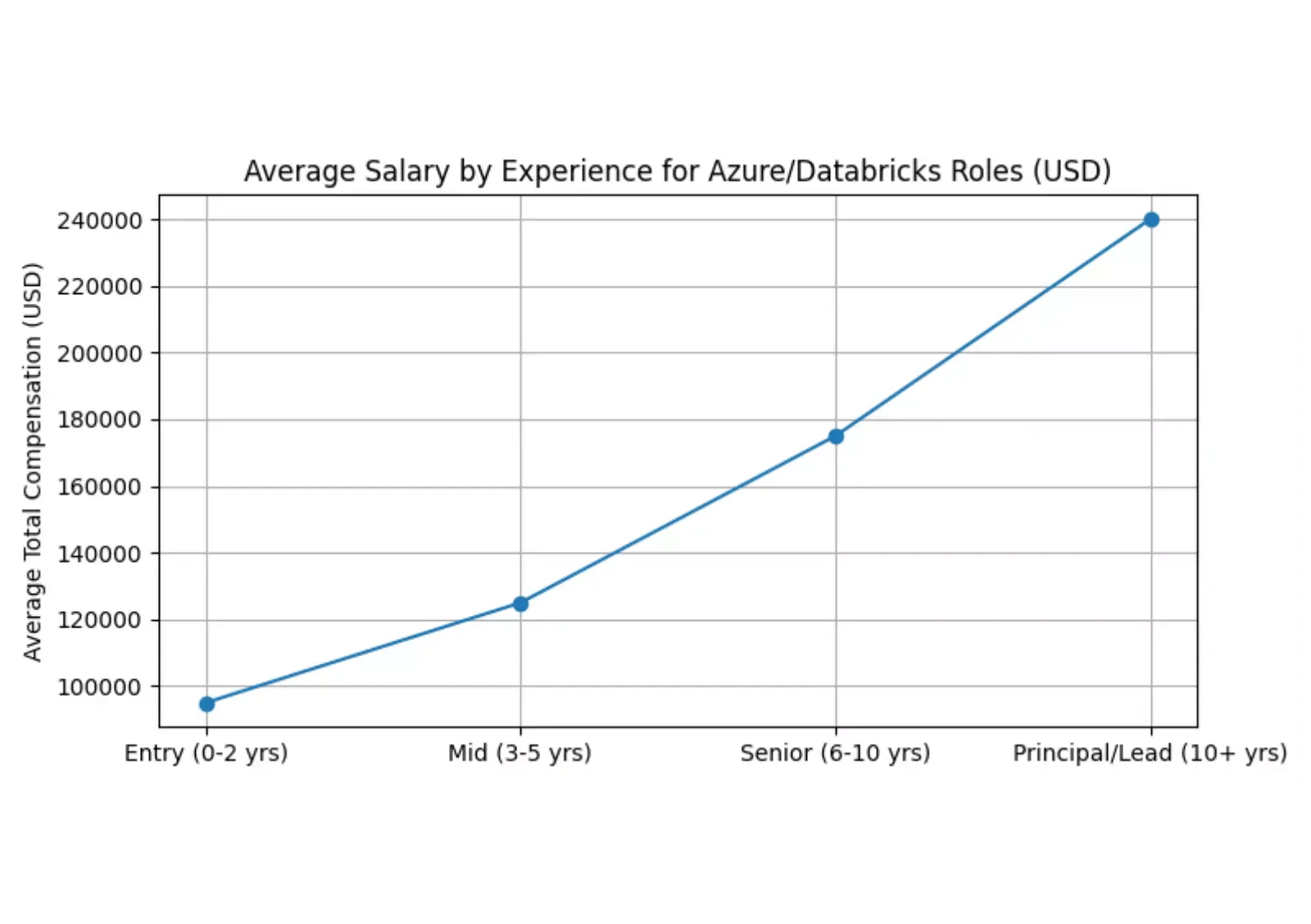
Sources indicate average total compensation for roles involving Azure Databricks commonly centers around $100k–$125k but can scale substantially for senior and staff engineer levels at major companies (see aggregated salary reports). The salary curve plotted above illustrates a realistic progression based on market signals.
Note: compensation varies widely by country, company size, equity, and individual negotiation. Use the graph above as a rough reference, not an exact guarantee.
Companies hiring Azure Databricks professionals
-
Large enterprises and cloud-first companies: Databricks serves large enterprises across finance, telecom, manufacturing, media, and retail — translating into job openings. Databricks itself and major consultancies (Infosys, LTIMindtree, Accenture, Capgemini) commonly hire Databricks-skilled engineers. You can find many active listings for “Azure Databricks Data Engineer” on job platforms. LinkedIn+1
Examples of employer categories:
- Product/cloud companies building data/AI features
- Consulting and systems-integration firms offering implementation services
- Enterprise industry verticals (banking, healthcare, retail, media)
- Cloud providers and platform teams within large organizations
9. Roles & responsibilities (typical day-to-day)
Azure Databricks Data Engineer
- Build scalable ETL/ELT pipelines with Spark and Delta Lake.
- Tune Spark jobs for performance and cost-efficiency.
- Implement data ingestion from cloud sources (Event Hubs, IoT hubs, S3/ADLS).
- Automate job orchestration and monitor production pipelines.
- Ensure data governance, lineage, and quality (schema enforcement, tests).
- Collaborate with data scientists to productionize ML models.
Data Scientist / ML Engineer on Databricks
- Prototype models in notebooks, scale training using distributed Spark or MLflow.
- Register and track models, set up CI/CD for model deployments.
- Work with engineering teams to integrate models into production inference pipelines.
Platform/DevOps Engineer for Databricks
- Configure workspace security (AAD, SCIM, IAM), VNet peering, and networking.
- Manage cluster policies, cost controls, and CI/CD for code/notebooks.
Steps to prepare for Azure Databricks certification
Databricks offers role-based certifications and training; Microsoft docs and Databricks training resources are also helpful for hands-on learning. Typical preparation steps:
- Pick the certification that fits your role (Databricks has Associate and Professional level certs for Data Engineers and Machine Learning Engineers).
- Learn core Spark & Delta Lake fundamentals — RDD/DataFrame API, transformations, actions, Spark SQL, joins, partitions. Use Databricks free on-demand training and Microsoft’s Azure Databricks getting-started tutorials for labs.
- Hands-on practice: build real pipelines on Azure Databricks — ingest data into ADLS, build Delta tables, implement incremental loads, test job scheduling and failure handling.
- Performance tuning & debugging: practice optimizing joins, partitioning, caching, and interpreting Spark UI stages.
- Use official courseware & practice exams: Databricks training site and official practice tests help familiarize with exam format.
- Mock projects & portfolio: publish a sample project (GitHub) that demonstrates ingestion, transformations, Delta table usage, and a simple model training flow — helpful for interviews.
- Apply for exam & keep studying: schedule the exam via Databricks’ certification portal and continue hands-on review up to test day.
Conclusion
Azure Databricks sits at the intersection of scalable data engineering and enterprise ML. It’s an attractive skillset because it lets you build distributed data pipelines and operationalize ML while leveraging Azure’s cloud services. Market demand, analyst recognition, and large enterprise adoption mean Databricks skills continue to be valuable — particularly for data engineers, data scientists, and architects.
If you’re starting out: follow a structured learning plan (learn Spark fundamentals, practice on Databricks with real datasets, and pursue a Databricks certification). Use the charts above to visualize market opportunity and how compensation typically scales with experience.

What Is Java Selenium? Beginner’s Guide to Automation Testing
YouTube Analytics Explained: A Beginner's Step-by-Step Guide

No Comments Yet
Let us know what you think